W zeszłym tygodniu odwiedzili mnie panowie Ryszard i Zbigniew Łukoś z firmy ExMetrix prezentując rozwijaną przez siebie platformę do modelowania i prognozowania procesów rynkowych, gospodarczych czy demograficznych. Ponieważ narzędzie wydaje się warte uwagi poprosiłem panów Łukosiów o przedstawienie jakiegoś przykładowego modelu będącego efektem działania ich systemu. Dostałem model dla DAX-a na następne pół roku wraz z opisem, którego streszczeniem chciałbym się podzielić.
Pierwszym etapem działania systemu jest selekcja danych, które mają potencjalny wpływ na analizowaną serię (w tym przypadku zachowanie DAX-a). Do dyspozycji jest 11 milionów szeregów danych makroekonomicznych, rynkowych i innych.
Selekcja danych przeprowadzana była – w przypadku tego modelu – według 3 kryteriów: podobieństwa na poziomie widmowym, kryterium korelacyjnego z uwzględnieniem optymalnych przesunięć oraz kryterium “dedukcyjnego” (czyli po prostu zmiennych dobranych “ręcznie”).
W przypadku poszukiwania podobieństwa na poziomie widmowym modelowana seria danych rozbijana jest na składowe widma częstotliwości (czyli na składowe cykle). Podobna procedura stosowana jest do wszystkich dostępnych danych. Dla tych zmiennych, których widmo jest zbliżone do widma DAX-a algorytm wyznacza 2 główne cykle czasowe i dokonuje ich ponownego złożenia. Następnie dokonywane jest porównanie ekstremów (minimów i maksimów) tak uzyskanego złożenia dla danej serii i dla DAX-a. Do dalszego etapu przechodzą te serie, dla których te ekstrema najczęściej wypadają przed podobnymi ekstremami DAX-a czyli serie, których główne składowe harmoniczne (główne cykle) osiągają dołki/szczyty zwykle wcześniej niż podobne składowe harmoniczne DAX-a.
Takie główne składowe harmoniczne DAX-a i dwóch przykładowych serii danych (REIT – Crown Castle International Corp. oraz EU-28 Retail confidence indicator) wybranych tą metodą zilustrowane są na obrazkach poniżej:
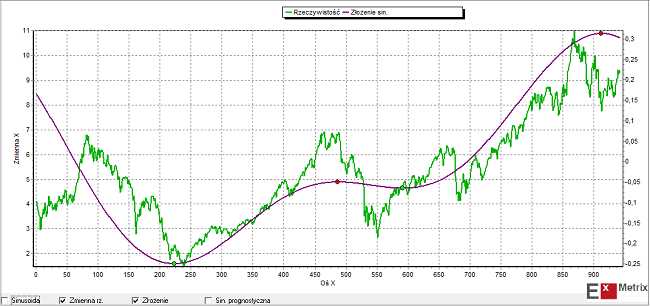
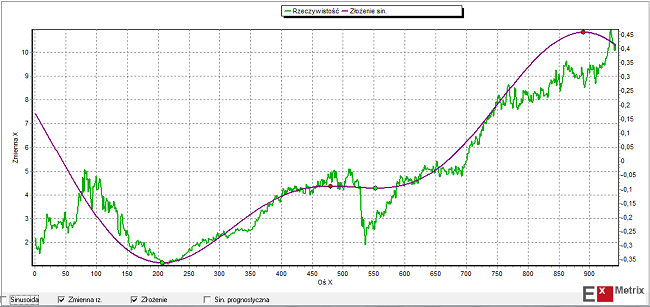
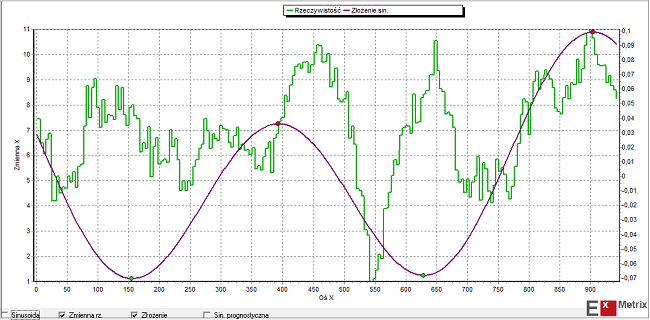
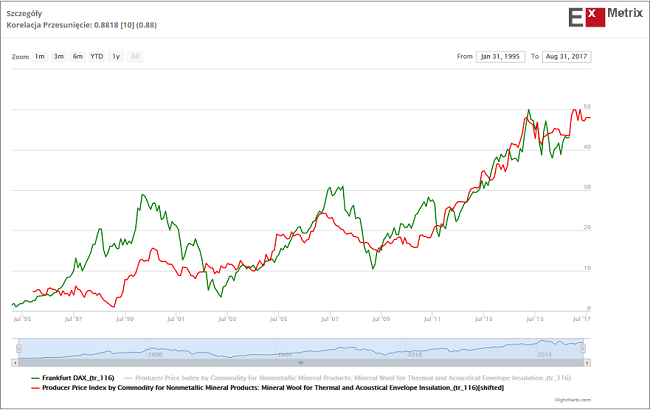
Druga metoda wyszukiwania potencjalnie użytecznych przy budowie modelu danych to metoda, którą sam często stosuję, czyli “metoda korelacyjna uwzględniająca optymalne przesunięcie czasowe”. Chodzi po prostu o poszukiwanie wśród milionów dostępnych serii danych takich, które wykazują wysoki współczynnik korelacji z daną, dla której model budujemy, przy odpowiednio dużym wyprzedzeniu w stosunku do danej objaśnianej.
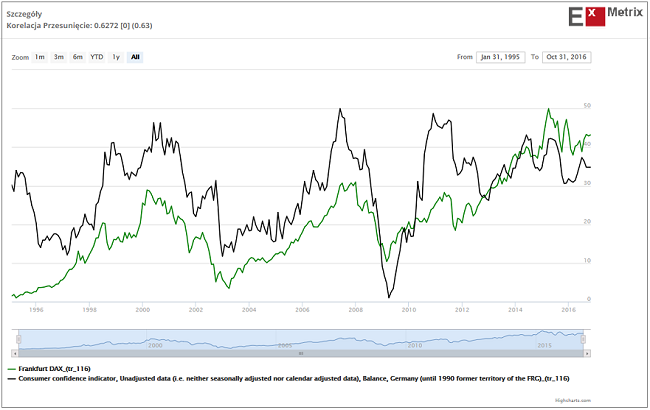
Znaleziona w ten sposób przykładowa seria danych, która przy średnio 10-miesięcznym wyprzedzeniu wobec DAX-a charakteryzowała się w okresie minionych ponad 20 lat współczynnikiem korelacji na poziomie 0,88, widoczna jest na poniższym obrazku.
Żeby nie było tak pięknie – to znaczy w pełni automatycznie – na koniec autorzy modelu wtrącili swoje trzy grosze i dodali do modelu serie danych, które nie zostały uznane za godne uwagi przez dwie poprzednie w pełni automatyczne metody, ale z jakichś względów cieszyły się estymą osób nadzorujących pracę komputerów. Przykładem takiej serii danych dodanych “po uważaniu” jest wskaźnik zaufania konsumentów dla Niemiec.
Po zakończeniu procesu selekcji zmiennych wejściowych system przechodzi do etapu optymalizacji parametrów modelu. Stosowana jest metoda “symulowanego wyżarzania”. Zacytuję autorów systemu:
“Jest to algorytm , który w procesie kolejnych iteracji poszukuje na tak zwanym zbiorze uczącym minimum błędu. Weryfikacja odbywa się na zbiorze testowym, który w tym przypadku tworzą notowania z ostatnich ośmiu miesięcy poprzedzających październik 2016. Algorytm wykazuje ponadto odporność na współliniowość zmiennych (choć pod tym kątem wyselekcjonowana grupa zmiennych jest zawsze dodatkowo weryfikowana). Nie ma też teoretycznego wymogu stosowania zmiennych stacjonarnych .
Model zawiera również moduł deterministyczny, co w tym przypadku oznacza uwzględnienie funkcji czasu, w tym uwzględnienia klasycznej dekompozycji zmiennej prognozowanej na trend i składnik cykliczny. W rezultacie wykonano dwa modele o różnej postaci matematycznej.
Pierwszy – to prosty model liniowy.
Drugi – to model potęgowy , w którym oprócz współczynników optymalizowane są również wykładniki potęg.”
Rezultaty działania obu modeli – liniowego i potęgowego – widać na poniższych obrazkach:
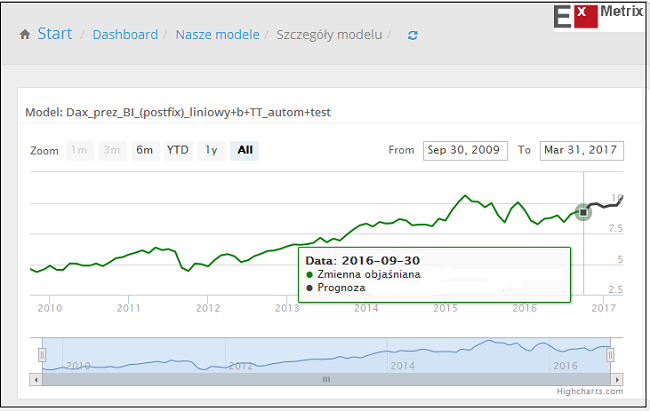
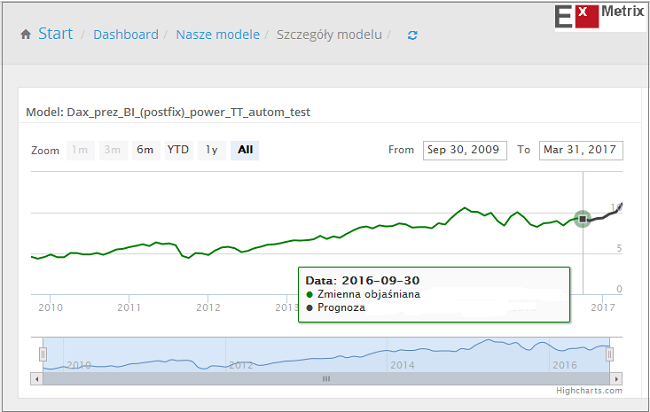
Jak widać oba modele sugerują wzrost DAX-a trwający przynajmniej do końca marca i sięgający okolic szczytu sprzed 1,5 roku (12374 pkt.). Za 5 miesięcy można będzie wrócić do tematu i ocenić jakość przedstawionych ExMetrixowych modeli dla DAX-a. Co ciekawe płynący z ich zachowania wniosek jest w miarę zbliżony – przynajmniej przez pierwsze pół roku – do tego, który pojawił się w moim poprzednim komentarzu: “Hossa do kwietnia, potem krach”.