Wracajmy do naszych baranów. Dzisiejszy wpis nie jest raczej przeznaczony dla osób, które chciałyby uzyskać prostą autorytatywną rekomendację kupna lub sprzedaży. Mam jednak nadzieję, że może zainteresuje i zainspiruje tych czytelników, którym zdarza się samodzielnie analizować sytuację gospodarczą lub rynkową i którzy nie boją się otworzyć Excela czy innego arkusza kalkulacyjnego (chociaż nawet to nie musi być konieczne). Chciałbym mianowicie przedstawić przykład zastosowania przykładowego algorytmu “analizy skupień” (grupowania, klasteryzacji). Brzmi groźnie, ale po prostu chodzi o metody znajdowania w większym zbiorze danych elementów podobnych. Zastosuję jeden z algorytmów tego typu do problemu, którym zajmowałem się tu dwa tygodnie temu (“W USA przemysł jak w 2004 roku, usługi jak w 2000”).
Zanim przejdę do rzeczy chciałbym zwrócić uwagę na najnowszy komunikat Nomury, w którym analitycy tego banku zwracają uwagę na to, że na ostatnich sesjach lipca “The stock market just experienced the most seismic shift from growth to value since Lehman Brothers“. Chodzi o gwałtownie osłabienie akcji spółek z sektora FAANG (Facebook, Amazon, Apple, Netflix, Google/Alphabet) czyli najpopularniejszych spółek wzrostowych względem spółek “wartościowych” (“value stocks“). Czy to ma związek z wnioskiem, który otrzymałem 2 tygodnie temu analizując wartości wskaźników ISM za czerwiec nie wiadomo, ale warto obserwować dalszy rozwój sytuacji. 1,5 miesiąca temu sugerowałem, że dobrym momentem na pęknięcia inwestycyjne bańki w sektorze FAANG byłyby okolice października. Być może ostatnie osłabienie to jeszcze falstart – coś jak dwie 8-10 proc. 3-5 sesyjne korekty Nasdaq Composite w styczniu 2000, a więc na 2 miesiące przed szczytem ówczesnej hossy w sektorze IT, ale oczywiście pewności tu być nie może.
Ale wróćmy do problemy znalezienia dla obecnej sytuacji w amerykańskim przemyśle analogów z przeszłości. Użyję tego samego co 2 tygodnie temu zestawu 10 subwskaźników z raportów ISM Manucturing (dane do czerwca włącznie, bez wczorajszego raportu za lipiec), ale do znalezienia podobnych do czerwcowego epizodów historycznych użyję innego narzędzia: programu PAST3 autorstwa Øyvinda Hammera z Muzeum Historii Naturalnej przy uniwersytecie w Oslo (“Hammer, Ø., Harper, D.A.T., Ryan, P.D. 2001. PAST: Paleontological statistics software package for education and data analysis. Palaeontologia Electronica 4(1): 9pp.“).
Past is free software for scientific data analysis, with functions for data manipulation, plotting, univariate and multivariate statistics, ecological analysis, time series and spatial analysis, morphometrics and stratigraphy.
Proponuję od razu klikną tu i ściągnąć sobie ten darmowy programik (5 MB). Uruchomienie go zajmie kilka sekund (nie wymaga instalacji). Oczywiście można też użyć jakiegoś innego programu do analizy statystycznej (Statistica itp.)
Program jest bardzo rozbudowany, ale nas dziś interesować będzie jedynie opcja oznaczona na górnym pasku jako Multivariate (analiza wielowymiarowa) i zawarte tam różne algorytmy klastrujące, którymi posłużę się do znalezienia sytuacji w przemyśle przetwórczym USA podobnych do tej z czerwca. Najbardziej pracochłonną częścią zadania może okazać się ściągnięcie sięgającej lipca 1997 roku historii 10 subwskaźników raportu ISM, którymi posługiwałem się przed tygodniem. Gdy mamy ją już w Excelu, po prostu kopiujemy ją do programu PAST3, który sam wygląda jak arkusz kalkulacyjny, wcześniej zaznaczając w nim w lewym górnym roku opcje włączenie kolumny “Row attributes” i wiersza “Column attributes”, w których znajdą się odpowiednio daty poszczególnych raportów ISM oraz nazwy poszczególnych wskaźników. Potem zaznaczamy wszystkie dane, klikamy Multivariate->Clustering->Classical i dostajemy drzewko wyglądające tak (na czerwono zaznaczyłem nasz czerwiec 2018):

Ponieważ nic nie widać, to zróbmy sobie zbliżenie na gałąź otrzymanego drzewa, na której siedzi nasz czerwiec 2018 (a którą zaznaczyłem powyżej czerwoną ramką).
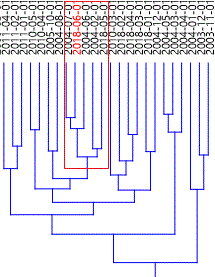
Jak interpretować otrzymany rezultat działania zastosowanego algorytmu analizy skupień (algorytmy klastrującego)? Bardzo prosto. Do czerwcowej sytuacji w przemyśle USA widzialnej przez pryzmat wartości 10 subwskaźników z raportu ISM Manufacturing najbardziej podobna była sytuacja z lipca 2004, potem z czerwca 2004. Dalej pojawia się luty 2004 oraz maj 2018 (czerwona ramka). Tą ostatnią datę oczywiście ignorujemy, bo jasne jest, że pomiędzy obrazem koniunktury w przemyśle USA w czerwcu i maju tego roku nie zaszły wielkie zmiany. Im dalej od gałązki odpowiadającej czerwcowi 2018 tym podobieństwo maleje (pojawiają się tam takie daty jak sierpień 2004, październik 2004, kwiecień 2010, maj 2010, marzec 2010, grudzień 2004, styczeń, luty i kwiecień 2011 itd.
To (lipiec 2004) jest podobny wynik, co uzyskany 2 tygodnie temu (luty 2004) za pomocą znacznie bardziej prymitywnej metody.
Oczywiście niewielu z nas tak naprawdę przejmuje się bardzo koniunkturą w przemyśle USA. Interesuje nas raczej kwestia przyszłego zachowania cen na rynkach. Powtórne pojawienie się analogii obecnej sytuacji do tej z 2004 roku sugeruje łagodny przebieg trwającej najprawdopodobniej cyklicznej bessy na rynku akcji (a la 2004-2005).
Oczywiście na dalszych miejscach pojawiają się takie daty jak kwiecień 2010 (czyli zaraz będzie korekcyjny “Flash Crash”), czy nawet okres styczeń-kwiecień 2011 (w kwietniu 2011 zaczęła się na S&P 500 szybka półroczna bessa), więc nie można tezy o analogii z 2004 rokiem traktować jak słów wyroczni.
Oczywiście ktoś zapyta się, czy to w ogóle tak działa, to znaczy, czy z faktu podobieństwa danej sytuacji w przemyśle USA do jakiegoś epizodu z przeszłości wynika jakieś podobieństwo zachowania rynku akcji po obu momentach. Postanowiłem zrobić test. Załóżmy, że jesteśmy na początku lutego 2016, czyli znamy dane ISM za styczeń i zastanawiamy się, co one mogą znaczyć dla rynku akcji. Wklejamy dane do PAST3 klikamy Multivariate->Clustering->Classical i otrzymujemy poniższy wynik (wyciąłem interesujący nas fragment drzewa):

Czyli na początku lutego 2016 otrzymujemy informację, że sytuacja w styczniu 2016 zdawała się być podobna do tej z (w malejącej kolejności) listopada 1998, października 1998, września 1998, sierpnia 1998, lipca 1998 i czerwca 1998. To wynik sugerujący, że nowa cykliczna hossa (odpowiednik hossy październik 1998-marzec/wrzesień 2000) się właśnie rozpoczęła, co jak się okazało było jak najbardziej prawdą:
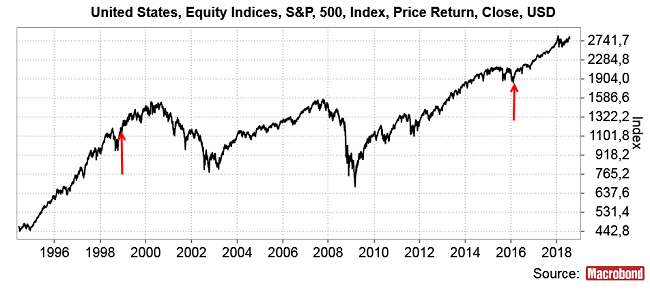
To oczywiście może być przypadek, ale mam nadzieję, że ten obiecujący wynik zachęci kogoś to pobawienia się w podobny sposób na innych zbiorach danych (np. wskaźnikach technicznych dla GPW) i podzielenia się rezultatami w komentarzu.
Ja ze swej strony pewnie od czasu do czasu będę wrzucał jakieś mam nadzieję interesujące zastosowania tej metody.
Podsumowując: algorytmy analizy skupień mogą być potencjalnie interesującą alternatywną techniką badania gospodarki i rynków. Dla przemysłu w USA analogia z 2004 rokiem została potwierdzona, ale oczywiście należy z nią uważać, bo sektor FAANG zapewne w małym stopniu zależy od tego co się dzieje w przemyśle Stanów Zjednoczonych (a potwierdzenia analogii 2016-1998 sugeruje, że prawdziwa może być analogia 2018=2000).